Introduction
In 2010, Facebook built a graph of user interactions and behaviours. Then it started growing really fast, selling ads, and gathering data. Then the ad targeting got really, really good.
Most people don’t know just how good — platform advertisements are just a slightly annoying feature that occasionally pitches you something very relevant. The actual conversion rates and ROI numbers are harder to appreciate without being involved in the Meta Ads Platform in some way.
In 2025, Anthropic launched Claude Sonnet 3.7, which included the ability to do useful programming work with tool calls. It spent the rest of the year getting very popular, and Opus 4.6 is now a really good agent.
Most people don’t know just how good. If you aren’t a programmer, a tool that can build multi-layered web service on your computer isn’t much different than Lovable. All they see is prompt in → finished product, when the meta-skill that’s improving is their performance on long-running, underspecified tasks.
Even fewer people appreciate how Facebook got so good. It’s hard to imagine how powerful “user data” can be if you aren’t aware of the range of what they’re tracking;
- Obvious metrics like content engagement (likes, watchtime) and profile information (biodata, photos, friend graph, etc)
- Subtler signals like dwell time, profile interest, etc.
- Underrated data that occurs off platform and is captured from Facebook’s Pixel (page views, add to cart) and Conversions APIs (purchases, refunds, returns).
With agents, we’re watching a similar story play out. Claude is an orange mascot that seems to get magically more capable at actual work with each version release. The “how?” is disguised under lab rhetoric of “straight lines on a graph” and “we’re so good at model training”. This is an incomplete picture, but it isn’t obvious why unless you understand what really goes into training agentic models.
This essay is about an underrated driver of these improvements: a form of data we call “work data”, and explains how/why it became a uniquely valuable asset.
So… what is work data?
We could have called it “interaction data” or “expert loops” or something even more jargon-y, but we found the humble “work” to be an honest, accurate description. If the image it brings to mind is an all-seeing eye, watching thousands of people work on a computer, and slowly learning and improving itself based on what it sees… you’ve almost got it.
Go one step further, imagine the all-seeing being was talking to each human as they worked, asking questions and updating on feedback. A partner-in-work that the human is trying to make as productive as possible, generously handing out advice and correction. That’s a truer picture of what a valuable source of work data looks like.
It’s easy to underrate how much of it you produce in your interactions with agents. It is produced during interactions between people too — but rarely recorded in all its special minutiae. None of our communication mediums encouraged it, nor was there a real reason to. This is why work data is a fairly novel form of data, it wasn’t worth capturing until very recently.
Below is a list of interaction examples, hopefully each one results in a jolt of recognition (“yeah, I do that!”).
- Specific expert direction/instruction (“merge these two modules…”)
- Justification: (“ …because they duplicate features”)
- Context management (“please pay attention to XYZ”)
- Intervention/correction (“stop, undo that and do it this way instead”)
- Metis/tacit knowledge (“Use this tool, not that one”, kids these days use
/skills) - Quality bars (“Okay, now we’re done”)
- Priorities/conditionals (“Make sure X is always true”)
- Patterns: (“when in scenario X, do Y”)
- Task selection from expert knowledge: (“let’s combine these two synergistic ideas”)
Now that you have a felt sense for what work data looks like, here’s a more concrete definition:
It’s the traces of workflow…
The record of work that arises from a session of active interaction, decisions that arise in pursuit of a long-running goal. Not data that comes from static context (like docs) or just the output at the end of a session.
The list above included examples of what these records might look like, and you can build your own list by answering the question: “what do you find yourself telling agents often?”
…captured within the tools of the trade
There is a tempting category error here: ChatGPT is widely adopted by white collar professionals. Surely the labs are seeing these workflows?
Chat interfaces capture the initial prompt, context, and output. From these, labs may learn preferences and satisfaction, but are not seeing the execution that happens in the tools of the trade. Even Notion, which may have some of the best data on workflows and which tools are integrated, will fall short here, because it’s not where the work happens. The path from idea to execution is long, uncharted, and invisible to these surfaces that only see content.
Work data comes from the surface where the work happens. Think about the canonical tools for each domain:
- In finance, Excel is where models are built, iterated on, and used to make decisions.
- For designers, the process lives in Figma or Photoshop. Layers, edits,
- In logistics, scheduling and quoting shipments happens largely over email
What do these traces actually look like?
The most useful work data doesn’t just consist of the name of the tool, and a list of “decisions taken”. The more detailed the interaction and the specifics of the environment, the more valuable it is for training agents that work with that tool.
So a good trace is just “the whole session”, captured in as much fidelity as possible.
- reasoning traces
- user acceptance/feedback
- task-specific tool calling
- specification of the task
- details of the task domain
- context management
Coding agents provide the easiest example. You can read an entire session in the form of text messages back and forth between the user and the agents, interspersed with tool calls and file reads/writes. Here’s one from Mario Zechner (a character who shows up later in this essay) and his tool Pi.
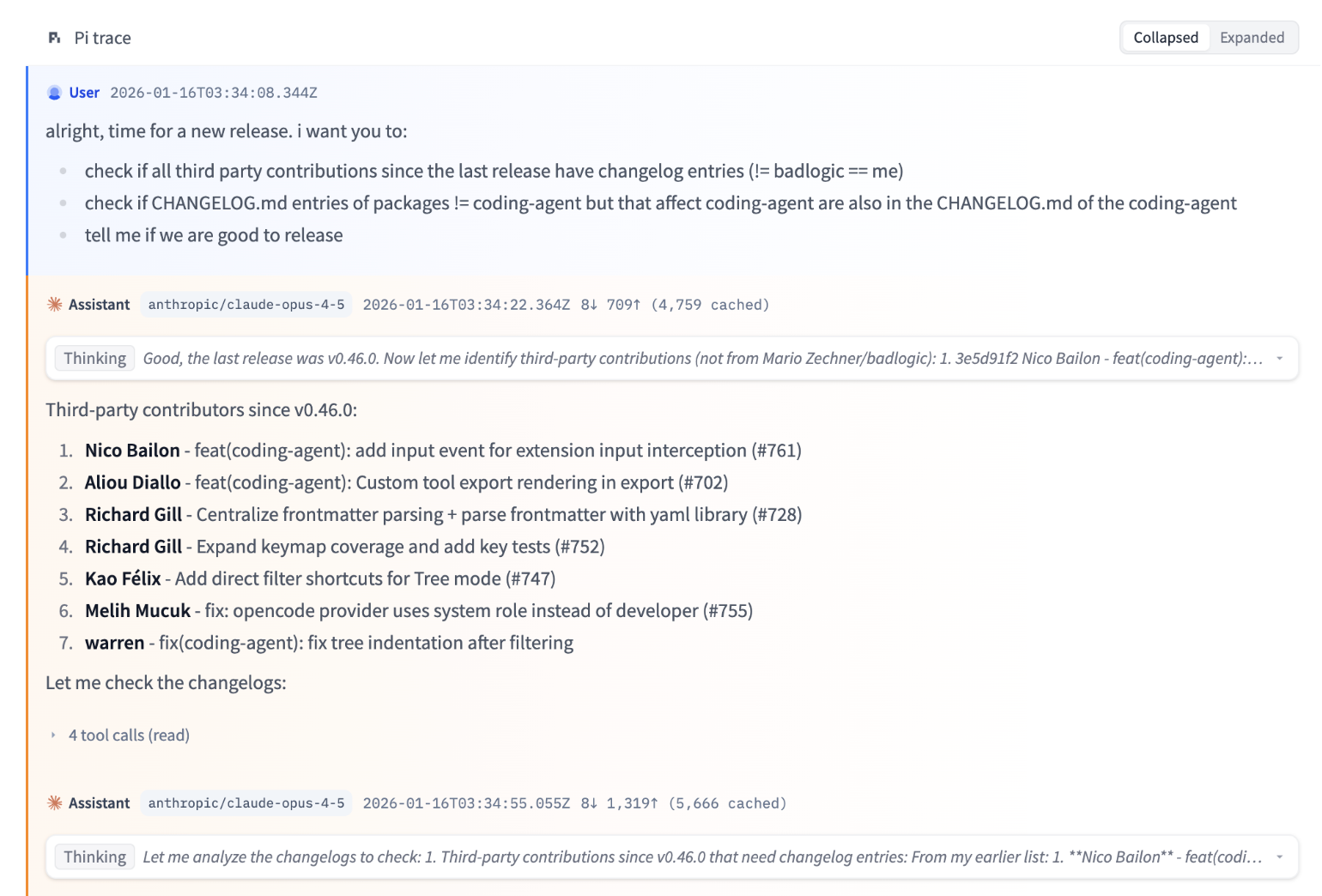
Why do labs care about work data?
From 2026 onwards, the labs are in the business of selling agents. They don’t have much choice in the matter.
A still-popular framing for AI products is “copilot for X” — an assistant or tool that plays a small role in a larger workflow. But it was only the limitations of the model’s capabilities that kept that product cycle going — the endgame was always going to be agents, because:
Agents are what users want.
Fundamentally, autonomous agent AIs are what we and the free market want; everything else is a surrogate or irrelevant loss function. We don’t want low log-loss error on ImageNet, we want to refind a particular personal photo; we don’t want excellent advice on which stock to buy for a few microseconds, we want a money pump spitting cash at us […]. Agent AIs will be chosen over Tool AIs because agents are what users want, lack of agency is something that will be penalized in competitive scenarios such as free markets or military uses, and because people will differ on preferences and some will inevitably choose to use agents.
Agents are also what enterprises really, really want. Demand for these is strong enough to make this whole thing not a bubble.
Labs have been raising money on the assumption that their TAM is all knowledge work, a market that requires selling digital workers, not tools. The end goal is the platonic “drop-in remote worker”, an agent that can be added to any company and quickly start being productive.
Agents have to be capable of acting as white-collar employees
White collar jobs consist of:
- Iteration: Figuring things out as you work, over multiple sessions
- Judgment: Applying hard-earned tacit knowledge
- Search + synthesizing: Finding relevant data and framing it usefully
- Tool expertise: Including folk practices and company norms
- Validation: Against multiple sources of truth: proprietary communications, reality
Seniority levels in careers correspond to increasing levels of competency in these skills. The ratio of skills changes usage too (experts can lean on judgement to save them iteration costs), but they are always present to some degree.
For agents to be effective workers, they will have to climb the competence ladder in these skills. They start with the basics of course (execute tool calls correctly, try multiple solutions), and will progress towards longer and more complex knowledge work requiring judgement and specialized knowledge.
Improving agents goes beyond simple task statements and corresponding work outputs, and into the realm of process. When the end goal is not fully known to either the user or the model at the start (it gets shaped turn by turn), the goal shifts from optimizing for individual requests using an immediate per-step reward (token likelihood), to delivering value across the full trajectory of the interaction.
Agents need to be trained
When agents are your main product, the work of doing “as little as possible as much as necessary” expands to much more than sending text completions over an API. The labs used to sell intelligence as something separable, abstracted, piped in, and paid for by the unit.
But they can no longer afford to treat the model as the site of intelligence and the application as a mere delivery channel. Because the separation of intelligence from application has proven to be worse than a model that already knows how to do the work well.
Our claim is that the new generation of agent-ready models have improved through RL training on work data (RLWD), and this is what makes them excellent active assistants out-of-the-box.
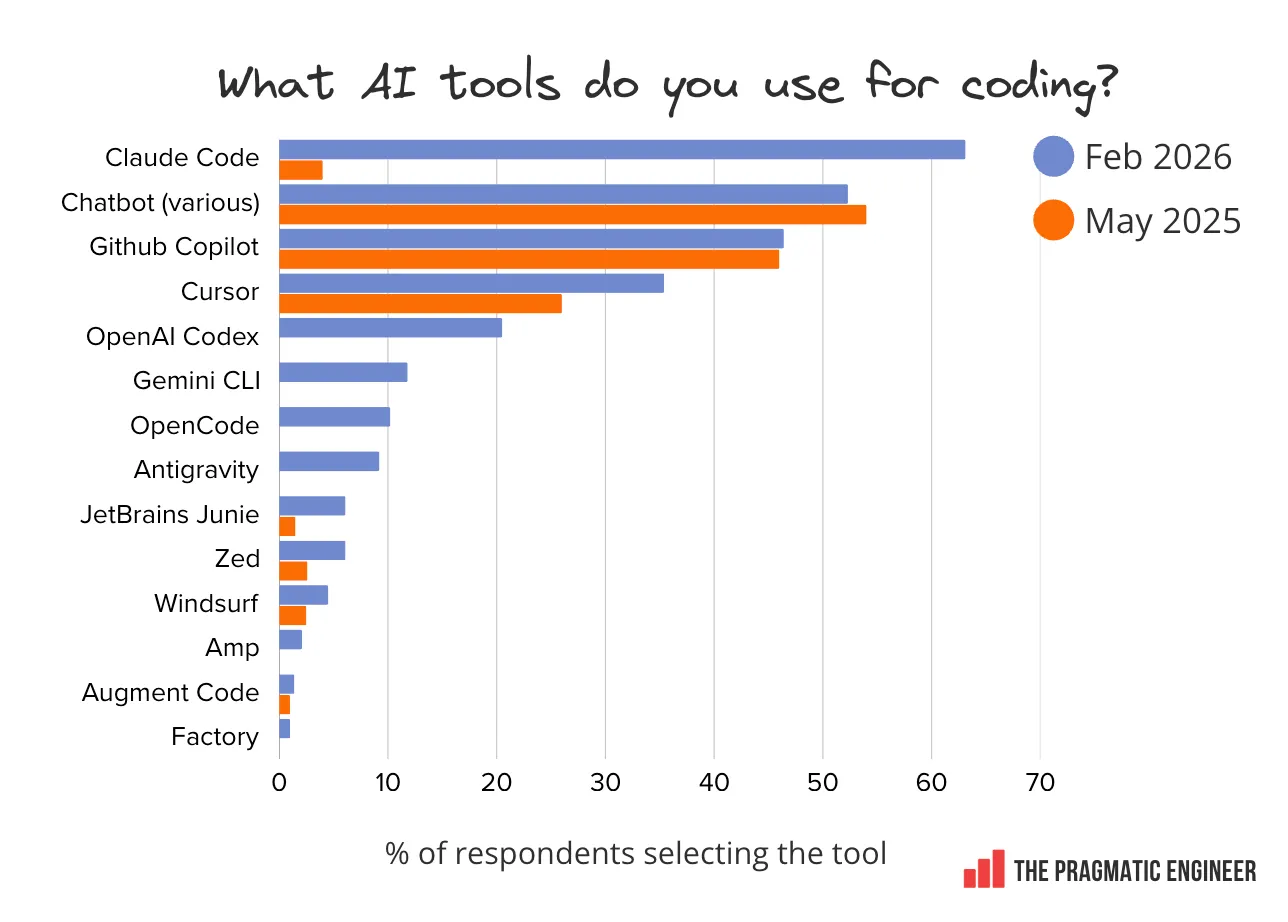
As an example, look at how quickly Claude Code took over the arena from Cursor. Cursor built one of the most valuable AI applications on top of APIs, but had no way to feed its live signals back into the model across the API boundary. The bar for the first agents were so low, simply having a co-evolution loop jumped Anthropic into the lead.
If training models as agents makes such a big difference, and slapping a harness on top of a generic smart model doesn’t work as well, why did the model-application separation last so long?
Part of the answer has to do with the nature of the first LLM products that were runaway successes:
- Code generation (Cursor, Lovable, Replit) worked because the output lands in an unusually structured environment. Compilers, tests, version control create feedback loops that make each response feel self-contained. This surrounding tooling does so much of the actual work—supplying context, verification, continuation—that the token stream seems like a stable, separable resource.
- Conversation (ChatGPT, Character.ai, Intercom) was based on producing clearly defined outputs for users, like in the domains of law or medicine. “ChatGPT, what does this contract say?” is a question that is answerable within a couple queries, and very predictable answers (the chances that model might have to do multiple searches through 100s of files are basically 0). Even a Deep Research report dealt with static data, and produced an artifact for one-time consumption.
Both these domains were dealing only with clear asks and cheaply verifiable artifacts. They were about producing outputs, not engaging in work.
If the pure harness lost in even in the most forgiving domain of code, where it was supported by verifiability (tests), version control (Git), self-documenting knowledge (code describes itself), and the harness was being built by domain experts (coders building for coders) — if even this domain could be yanked away from harnesses by labs that could RL on more work data… the broader argument is unavoidable.
Few agent-building companies (that are not labs) can afford to be honest about this reality, but here’s an admission from one of them.
These new models barely need to be told how to act like coding agents anymore. They’re now fully trained for that.
Thorsten Ball, The Coding Agent Is Dead
Training your super-intelligent, all-capable genius that lives in a data center to be better at using Excel or writing composable CSS might feel a bit like blasphemy if you believe in true AGI. But AGI comes second to being a good employee when you’re trying really hard to sell employees. You put the model in a fancy suit (cough, harness) and send them off to work.
But there are a few things that make it difficult to train these digital employees:
There is no internet-scale dataset of “white collar” work lying around
Kevin Lu at Thinking Machines made a sharper version of this point: the Internet is what unlocked generally capable models, not transformers. Train an LLM, but limit the dataset to every textbook and scientific paper (what we might consider the pinnacle of human intelligence) and the results are middling compared to today’s SOTA.
An LLM can produce novel outputs, but it is still sampling from a learned distribution: during training, it learns patterns from the data and constructs a mathematical model of those patterns. During inference, it uses that model to simulate what should be written next.
This is why we can’t just “make a smarter LLM who just knows how to do everything" — work data is a fundamentally different distribution from the internet corpus. Similar to how visual reasoning is hard because “nobody writes tomes explaining how to visually reason. We take it for granted, so we don’t write it down”, the text on the internet does not contain descriptions of “how to do job X in excruciating detail.”
If there’s no existing dataset that provides us with the distribution, maybe we can create one? What if we got a bunch of people to just work on creating massive datasets of simulated work? If imitation learning works for self-driving and computer use agents, why not try to apply it to all white-collar work?
Some players (see Surge’s Workforce) in the data market are certainly trying, but:
- Simulated work data is going to be very expensive to get to internet-scale.
- The data generated is also much narrower, there’s a higher chance of distribution collapse compared to an organic process like the internet.
- Worse, it’s prone to overfitting: even in self-driving — a much more defined problem than open-ended knowledge work — researchers couldn’t rely on simulated data alone. They had to leverage interactive correction data to prevent small errors from compounding over the trajectory.
Nor is there a “work RL environment” outside of actual work
Recent capabilities improvements in some fields (math and code in particular) owe a lot to a training paradigm called RLVR (Reinforcement Learning with Verifiable Rewards), that works very well for…well, verifiable problems.
- Run the code, feed the test result back to the model.
- Come up with the math proof, verify through a Lean formulation
- Generate UI code, compare it to a screenshot, note the visual difference
But when trying to use this “try things and learn through what works” approach feasible for other things, we run into a problem: verification loops are rare.
Imagine trying to run a business in which the only feedback given is whether you go bankrupt or not. In running that business, you make millions or billions of decisions, to adopt a particular model, rent a particular store, advertise this or that, hire one person out of scores of applicants, assign them this or that task to make many decisions of their own (which may in turn require decisions to be made by still others), and so on, extended over many years. At the end, you turn a healthy profit, or go bankrupt.
So you get 1 bit of feedback, which must be split over billions of decisions. When a company goes bankrupt, what killed it? Hiring the wrong accountant? The CEO not investing enough in R&D? Random geopolitical events? New government regulations? Putting its HQ in the wrong city? Just a generalized inefficiency? How would you know which decisions were good and which were bad? How do you solve the “credit assignment problem”?
Without verification, rewards are usually too sparse to be useful. Which means that “thinking harder” (i.e. scaling CoT (Chain of Thought)), also doesn’t make sense without a way for the thinking to be constrained by a ground-truth.
Work provides the data and environment for training agents
To be clear, we’re not claiming work data is the magic sauce that fed all progress for the last year or so. It doesn’t make them “smarter” in the way training a larger model on much more data does. Nor does it make them competitive coding geniuses, or capable of reasoning. Those capabilities arose from a plethora of different training approaches.
What work data does help with is the training of useful agents (take iterative action in service of goals, understand domain requirements, work collaboratively, etc.).
By providing a ground truth
It can provide real rewards, because the reference is the work itself, not a gameable proxy.
In simulated RL, a model that cheats simply posts a higher score. There’s no reference beyond the benchmark to call it out. In real-time RL, real users trying to get things done are less forgiving. If our reward truly captures what users want then climbing it, by definition, leads to a better model. Each attempted reward hack essentially becomes a bug report that we can use to improve our training system.
Cursor research blog, Improving Composer through real-time RL
People using the agents for real work play the role of a “soft verifier” for the generating LLM. The reward mechanism comes from their judgement of the consequences — the backstop is their desire to do good work. RL training on acceptance rates, context management, tool use guidance, etc. is what allows this judgement to pass through to the model itself.
From an ever-growing source (like enterprise product)
To improve an intelligence product, you need to know where the model failed in the workflow. You need to see the test that broke, the user’s clarification that the model misunderstood. You need to help users manage things like context, reasoning levels, cost structure and task specification.
The best way to collect data on all these things is to control the workspace and keep users engaged in them. Currently, labs do this by building harnesses and trying very hard to get people to use them. They’ve started to build apps for specific verticals, because the application layer is the one that sees where intelligence fails in real work. While the model does supply general capability, the application is where that capability is forced into contact with concrete tasks, user corrections, and shifting intent. You can’t shortcut it by sourcing data from elsewhere.
This is why labs have been forced to get into product, moving from “genius model” to building Electron frontends as wrappers for coding agents. The models need a product layer, perhaps more than the products need the models.
The “data = fossil fuel” perspective treats data like a static amalgam, but we can now produce more data through agents interacting with users. The best products for this purpose don’t require a firm to re-organize itself around making all its knowledge explicit, but focus on capturing interactional data that can form the basis of new kinds of priors.
Not consumer applications though, since:
consumers just do not have very many long chains of tasks which can be automated end to end to unlock huge value. their chains are shallow almost always in enterprise, org processes form very long chains, so the reward for automation is much higher. why are most consumer AI agent demos still effectively at the “book a flight for you” level of complexity? that’s not a coincidence
Herbie Bradley, tweeting
Consumers usually lack the expertise necessary to provide feedback and correction to the model, and are not looking to engage in iterative processes either.
What the future looks like…
Until the tail end of 2025, models were largely differentiated on cost and benchmarked capability. But we’re seeing a new differentiation emerge from data — and who has access to it.
As we progress towards online learning, models will become more varied and differentiated. Many may start from a common base, but they could specialize into a particular domain or use case, depending on the proprietary data streams and feedback loops they inhabit.
This will have many consequences…
Progress across domains/industries
Schleppy progress
Two visions of AI development:
A: Massive scaling, achieve AGI, solve everything at once.
B: Teach AI to solve everything, one problem at a time.This year, AI companies will quietly realize that B is the right path (if they haven’t already). B will become common knowledge in the next ~3 years.
Sam Harsimony, skeeting
For industries where products can’t penetrate fast enough, adoption needs more of a push. The work data isn’t going to gather itself.
Anthropic’s Enterprise AI Services Firm Partnership: Anthropic, Blackstone, Hellman & Friedman, and Goldman Sachs today announced the formation of a new AI-native enterprise services firm that will work with companies to rapidly bring Claude into their core business operations. The new firm is a standalone entity with Anthropic engineering and partnership resources embedded directly within its team.
OpenAI FDEs: We pair OpenAI Forward Deployed Engineers (FDEs) with your teams, working side by side to help you develop the best practices to build and run agents in production. The FDEs also give teams a direct connection to OpenAI Research. As you deploy agents, we learn not just how to improve your systems around the model. We also learn how the models themselves need to evolve to be more useful for your work. That feedback loop, from your business problem to deployment to research and back, helps both sides move faster.
Data markets
Traces are going to be captured across more tools and domains. Here’s a dataset from everyone’s favourite whiteboarding app, as an example. It seems plausible that these datasets get sold to model trainers. The “expert data” sellers like Mercor and Surge will have to face this competition as well as the fact that model labs are going direct through building their own expert-facing products.
Longer horizon tasks
As agents improve their domain-specific judgement over short tasks, they will need less active feedback, and a new challenge will present itself: feedback loops for long, less-supervised goals.
Most interactions today are still relatively short, so Composer receives user feedback within an hour of suggesting an edit. As agents become more capable, though, we expect they will work on longer tasks in the background and might only return to the user for input every few hours or less.
This changes the kind of feedback we have to train on, making it less frequent but also crisper, because the user is evaluating a complete outcome rather than a single edit in isolation. We’re working to adapt our real-time RL loop to these lower frequency, higher fidelity interactions.
Cursor research blog, Improving Composer through real-time RL
We expect to see code be the first to achieve long horizon success, because of its:
- Verifiability, so correction can take the form of high level feedback about the complete outcome, instead of validation of every step/aspect of the output.
- Techne-based nature, which means that its RLWD-based learnings generalize across situations and time horizons.
Other domains, especially anti-inductive ones, might not do so well since they require tackling ever-changing scenarios. Baking the skills into the model is not the right approach here: “run a good marketing campaign” is a tricky thing to RL compared to simply “build a microservice that does X.”
Cross-domain quirks
The models are monolithic offerings, which is an advantage in some ways. The behaviors that make them a helpful coding model (learning when to ask for clarification, for example) also generalize to most other domains.
But the new influx of work data going into their training leads to a class of mannerisms shaped by a myriad of worker preferences, and will be noticed in work situations.
Over-clarifying
> Ask it if I can do something
> It says “no you can’t [incredibly twisted restatement of what I asked but also not at all what I asked]”
> It then tells me how to do the thing wonderfully
> And finishes with an insulting “But you can’t just [stupid thing I never actually said]”Ryan Florence, tweeting
More/less instruction-following behaviour
It is both a thing to exploit and a curse that GPT is so good at instruction following. But i as a human am lazy and bad at giving instructions. Implicit in almost every prompt I give is “also understand the set of principles I am using to give this prompt and apply that higher level guidance to everything you do”. Alas, I often devolve into rapid fire steering before catching myself that now is the time I need to prompt more diligently. Really I cannot wait for the models to pad their stats on conscientiousness.
Ryan Lopopolo, tweeting
When we began testing GPT‑5.5 in Codex, OpenAI employees immediately noticed the strange affinity for goblins, and we added a developer-prompt instruction(opens in a new window) to mitigate. Codex is, after all, quite nerdy.
Nobody:
Somebody somewhere occasionally: uses the term “smoke test” very occasionally
Claude Opus 4.7 every other sentence: let’s run a smoke testAaron Bergman, tweeting
Agentic focus requires models to follow instructions carefully: do everything explicitly stated and don’t do things not stated, generally. In contrast conversational models are better when they can “read between the lines”.
@distributionat, tweeting
i need someone at @OpenAI and @AnthropicAI to teach the models that while prototyping, backwards compatibility is just a bad idea
Leandro Ostera, tweeting
i am so confident that our frontier models are losing a non-trivial amount of capability due to priors about what’s reasonable to just ask “someone” to do and what’s not reasonable
@snwy_me, tweeting
More closing of loops
Contrast AWS with intelligence. The former improves its core services without needing your business data; product health is measured through infrastructure vitals like latency and throughput, so Amazon only needs to know how you access the service, not what you are using it for.
AWS is a positive-sum ecosystem in the truest sense. The provider improves the foundation; the application handles the end-user experience. The boundary between them holds because both sides get what they need without crossing it.
The intelligence API borrows this language of openness and modularity, so it is natural to assume the same positive-sum logic applies. But in practice, APIs force the model provider to either accept commodity margins or destroy its own customer base by competing with it in order to gather the all-important work data.
In a healthy system, the model and application layer would co-evolve through iteration. But in severing this feedback loop, the resulting state is several vertically integrated companies in hyper-competition instead of a positive sum ecosystem of complementary players. If they’re going to train and sell agents, why let others compete?
Product-model partnerships
Though Cursor has amassed valuable data, it remains structurally a reseller. The fact that Anthropic was able to compel Cursor to shut off access for one of Cursor’s own customers reveals the power dynamic that the API boundary creates.
The partnership between xAI and Cursor is about the only remaining path for them to close the feedback loop: own the full stack. We will see more acquisitions driven not by synergy but by structural necessity, more vertical integration that solves the feedback problem by eliminating the boundary entirely.
Co-evolution in the presence of privacy requirements
Anthropic held back from training models on consumer data, but reversed their default opt-out policy in August 2025. OpenAI, in contrast, had always trained on consumer usage.
But neither Anthropic nor OpenAI train on enterprise data, likely because of stringent policies around privacy and data retention. And that enterprise standard is probably not going to go away.
In addition to in-house forward-deployed engineers, both labs have incorporated separate entities to further deploy their products (OpenAI’s The Deployment Company and Anthropic’s unnamed joint venture). This can be read as a bid for more work data access that circumvents privacy expectations.
We launched the OpenAI Deployment Company as a standalone business unit so it can develop the operating model, pace, and customer focus this work requires. At the same time, the OpenAI Deployment Company will operate as an extension of OpenAI, keeping customers closely connected to the research, product, and in-house deployment teams shaping frontier AI.
OpenAI, OpenAI launches the OpenAI Deployment Company to help businesses build around intelligence
Confusing messaging
Since they were founded, the labs have been loud about building AGI, the all-capable model that replaces everything and everyone by virtue of its raw intelligence. But this clashes pretty strongly with their current push to sell solutions for specific verticals, and a recent narrative switch around “just building tools”. We expect this confused messaging to continue…
They will say one thing:
if you are building knowledge worker agents that require more setup than the equivalent of “here’s a laptop in the mail show up to the office Tuesday at 8:30am” you’re ngmi
Ryan Lopopolo, tweeting
While also saying the opposite:
While alternative coding harnesses may have short term lift, they will be bitter lesson’d away. I am bearish on any harness that doesn’t come from the lab whose model you are using. You’re fighting against post-training.
To put a finer point on this, you know how like, ioctls are like “huh that’s weird but I guess whatever it’s what we’ve got we can work with that”? It is exact the same with like, the particular JSON construction the Codex shell tool uses.
The model used to mangle nested quotes in this monstrosity RPC all the time but now it does not and it does not matter that the API is bad because billions of failed invocations are used to train to the harness we have, not the harness we deserve.
Ryan Lopopolo, deleted tweet
Obviously, “AGI, but only with our harness” is a contradiction in terms.
Models trained through work data are inherently differentiated and just as protected as proprietary enterprise datasets are. The idea that a “model” is a general artifact, and not as proprietary as the business itself, is an indication that we are still in the early innings of wide-scale AI deployment.
Insular optimization goals
Work data also gives the labs a pathway to better unit economics. Anthropic has already indicated it needs telemetry to optimize usage:
“Third-party harnesses using Claude subscriptions create problems for users and are prohibited by our Terms of Service.
They generate unusual traffic patterns without any of the usual telemetry that the Claude Code harness provides, making it really hard for us to help debug when they have questions about rate limit usage or account bans and they don’t have any other avenue for this support.”
Thariq Shihipar, tweeting
And that same telemetry gives them a lever to optimize unit economics through approaches like adaptive reasoning, which varies compute spend according to task difficulty. Having access to the raw work data (“task telemetry”) helps with classification. This will become increasingly important in a capacity constrained world.
Battles for independence
In response to labs trying to take over product surfaces, and force their own harnesses onto users, we can expect resistance from the people this affects (software companies, developers, etc). Moves and counter-moves of all sorts will be deployed.
Open work data
Gathering, using, and sharing work data captured from harnesses is one way for non-lab parties to retain some control. An early version of this is Mario Zechner’s call for sharing agent sessions/traces:
i believe we need to band together as a community and create a public, free to use repository of real-world (coding) agent sessions/traces. I want small labs, startups, and tinkerers to have access to the same data the big folks currently gobble up from all of us. So we, as a community, can do what e.g. Cursor does below, and take back a little bit of control again.
It remains to be seen how feasible this is, given that useful traces are harder to capture in domains outside of code, and the inevitable problems around privacy.
Right to bear harness
Developers as a group have always been tool optimizers, and harnesses provide the perfect tinkering ground. They will try to squeeze as much performance as possible out of open models.
As opposed to lab rhetoric (“the model is the product”), end users see the value in unhobbling, and take it seriously as an endeavor of its own.
One thing I’ve noticed about Harness discussion is there are some people who think it means *the cybernetics work you do to connect models to value* and others see it as a convention for terminal interaction tool shapes and there is some talking past one another btwn them
Josh Purtell, tweeting
…higher level of abstraction coordination mechanisms are far less dependent on fiddly details like JSON construction, and you benefit much more from a model-agnostic approach
so I expect a persistent scaffolding performance boost above the level of abstraction of claude code/codex, especially when the scaffolding can be customized for different tasks*
Herbie Bradley, tweeting
RL-as-a-service
The Composer series of models from Cursor, is a great example of a product company taking charge of shaping their agent through the model layer. Cursor looked at their work data and desired properties, and RLed an open source base model to satisfy their particular cost-speed tradeoffs. BYO posttraining.
But for RLWD to be feasible for more companies, the infrastructure and expertise needs to be more easily available. This is the exact bet Prime Intellect and Thinking Machines are making. RLaaS allows enterprises to post-train open source models on their proprietary work data without needing the in-house expertise, or handing off control to the labs.
Personal cost optimizations
Most work will not need frontier intelligence or closed source models. There will be an explosion in harness engineering for low-ceiling tasks, for the purposes of cost reduction, especially as more business-scale work starts to be done, and even small % improvements begin to add up. It’s possible this will also feed all the way back into the inference layer services that run open-source agents.