A broken pricing paradigm
Cursor, Anthropic expose cracks in cost structure and resource allocation
PART I: High variance in AI demand breaks unit economics and resource allocation at scale
The Cursor-Anthropic pricing drama earlier this year exposed a flaw in how we price and deliver open-ended AI workloads. The implications go far beyond margin squeeze and outages: it is a paradigmatic scaling problem, rooted in the physics of how large language models work.
Table of Contents
To recap the facts: the Cursor Pro plan launched as a classic SaaS subscription ($20 for unlimited usage). In mid-June, they reversed course on "unlimited" and charged for usage exceeding the $20 price point. It was later revealed that Anthropic had raised their prices before, and many concluded this to be the root cause.
Cursor's own explanation: "the hardest requests cost an order of magnitude more than simple ones." Their fix was to pass the heavy-tailed cost to users at retail token price from the cloud APIs.
Anthropic's subsequent rate limits are more revealing though, because they control the whole stack. The limits appear motivated by the same magnitude in demand: some Claude Code users reported burning $400+ worth of tokens on a $20 monthly subscription, based on the per token cost that Anthropic themselves publish.
But the limits Anthropic imposed were not token based, but "usage" based. Instead of a transparent "X tokens per week," users simply hit an unlabeled weekly cap and an equally opaque session-based hourly cap.
This reveals something important: Anthropic's session-based usage limits and weekly limits are a tacit admission that the token is not a stable unit of cost, nor compute.
A token is not a fixed, atomic unit of cost
We only consider token count as the static linear meter because we inherited the logic from inference APIs. But, a token does not represent a fixed unit of work.
This is obvious to anyone who works in inference, but if you’re used to calculating compute budgets based on linear API rates, it takes a second to sink in.
The intuition is grounded in the autoregressive nature of the transformer: Attention is quadratic with respect to current context size. (via @trickylabyrinth on X).
In layman's terms, the language model is looking at every previous token in the context window before generating a new token, which means inference APIs are linearly pricing fresh tokens whose compute cost scales quadratically.
The scaling law for compute is likely not purely quadratic, given optimizations like caching and compacting context. But no matter what, the underlying compute cost per token grows with context length. The Nth token in a conversation is an order of magnitude more expensive than the first.
There's signs that per-token pricing breaks down at scale: both Anthropic and Google charge different rates based on prompt length.
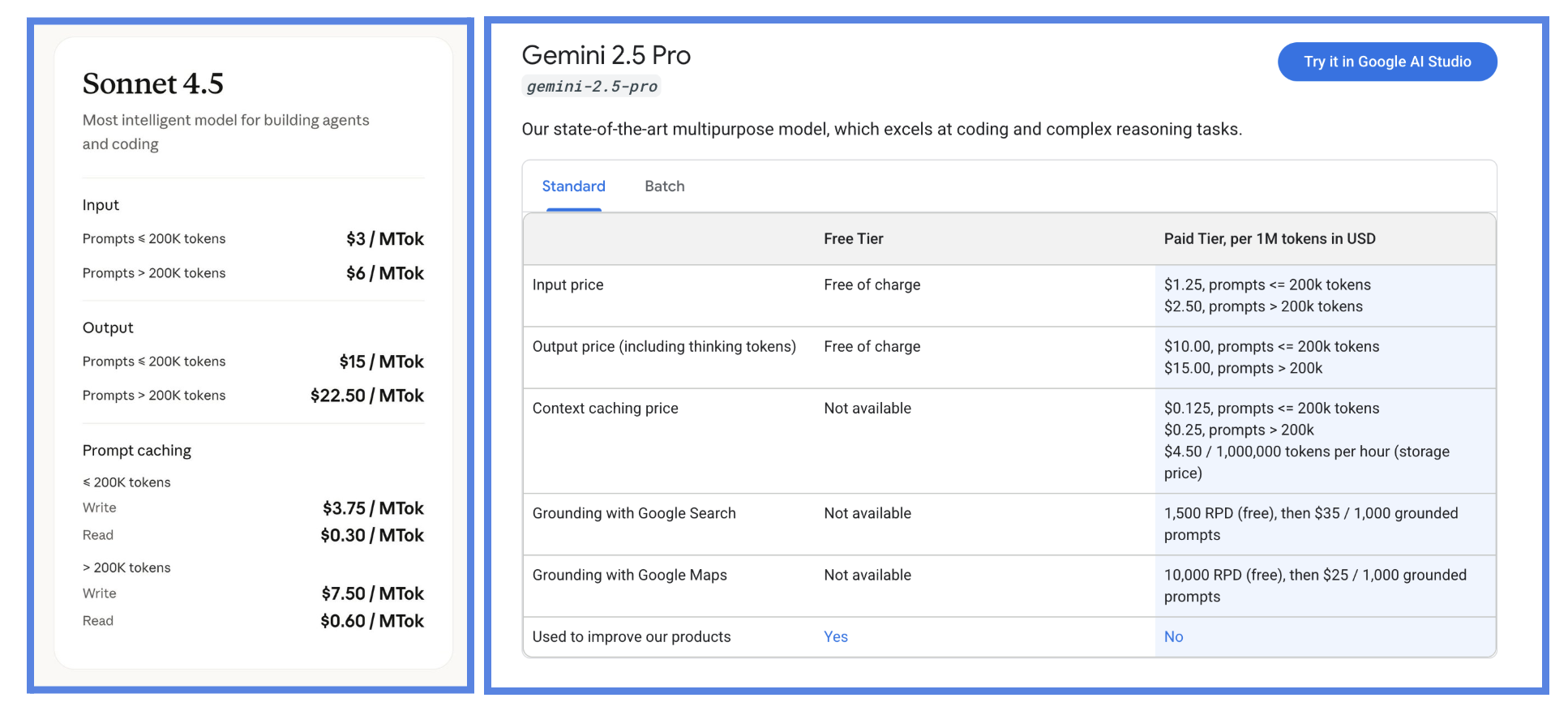
Charging higher API rates for nearly full context windows, and Anthropic choosing to impose request-level caps rather than trust the token meter for rate limiting indicate that one request can explode in compute, irrespective of token count. Their hedge is to sell a bigger pile of them and hope the tail stays inside that pile.
A token is variable in cost.
And tail risk compounds with usage
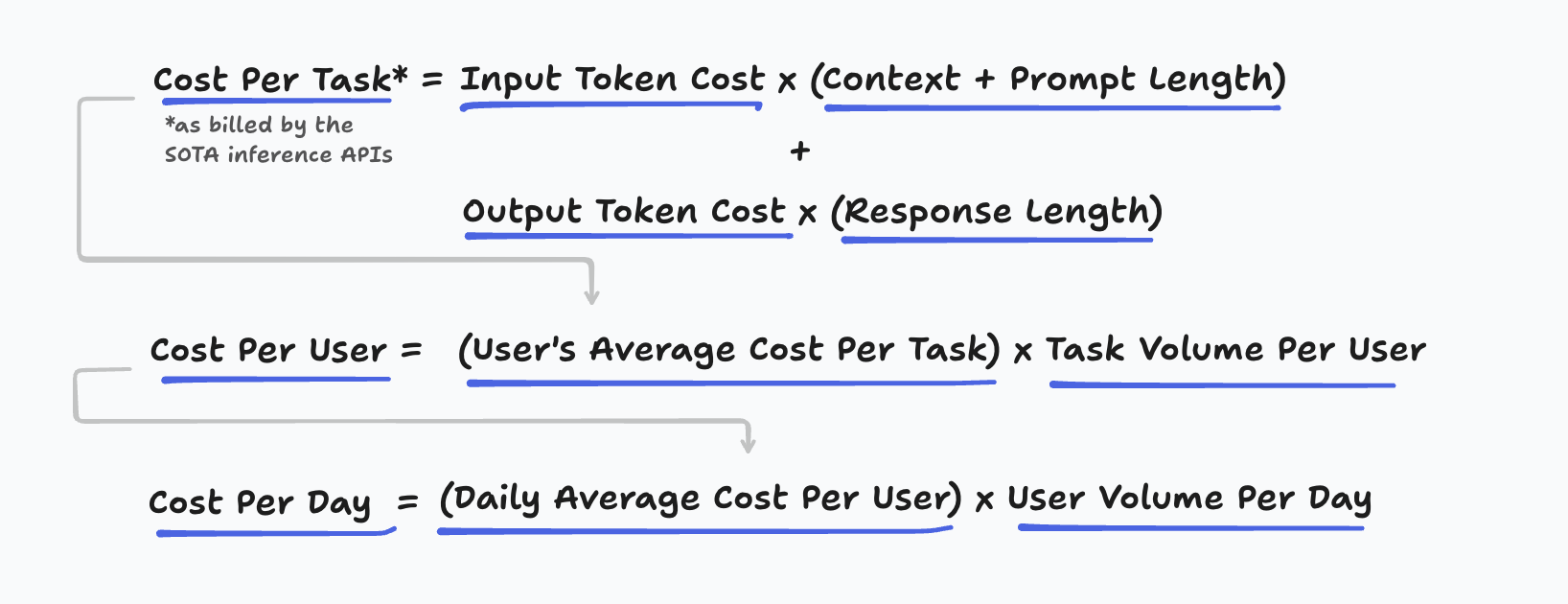
We have established that per token costs for inputs and outputs are variable. But the market shift towards agentic loops exposed that every cost input in AI-native software is highly varied.
Cost per user is a composite function of many moving variables. Notably, task volume per user, token volume per task, input token cost and output token cost.
When Cursor made its price change, some users hit the cap within 3-5 prompts: a clear sign of variance in task complexity and cost per task.
When Anthropic's usage limits were introduced, some engineers hit it within 8 days. Some run 8 parallel instances of Claude Code. Anthropic themselves said one user consumed "tens of thousands" on a $200 plan. These are clear signs of user heterogeneity and variance in task volume per user.
Traditional SaaS has variable costs too (like hosting, customer support and third-party service costs). But these costs follow the law of large numbers, and are normally distributed at scale. You can set a single subscription price that covers this average cost, plus a comfortable margin to absorb tail risk.
In the case of AI software, it is likely that these variable costs are fat tailed. The law of large numbers assumes finite mean and i.i.d. samples, but AI software has at least one dimension with infinite first moment and non-stationary tails. The sample mean keeps wandering instead of converging.
So let’s assume their aggregate daily cost is a composite of fat tailed moving variables. Cursor and Anthropic actively constraining demand, when neither have shifted towards “profit-maximizing” strategies yet, support this. Anthropic's usage limits are said to only apply to "5% of subscribers."
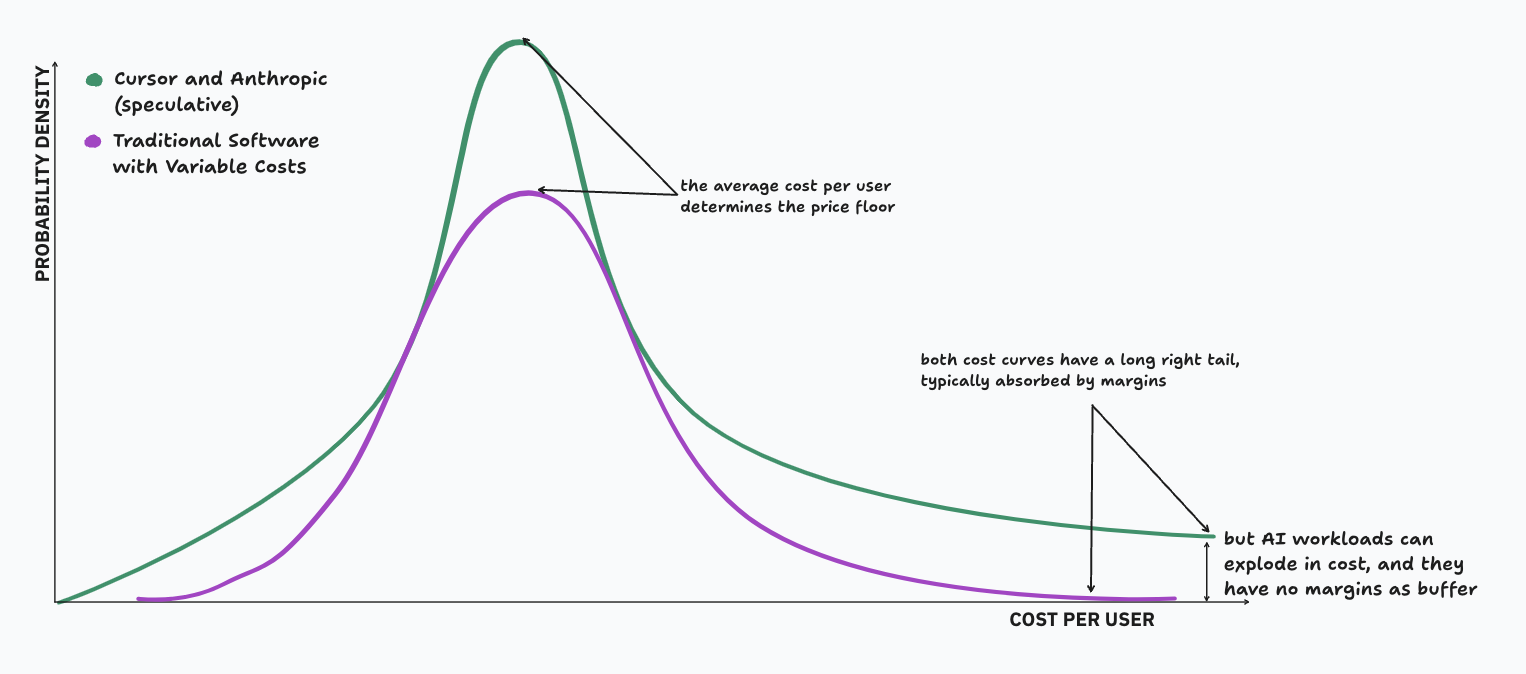
The fat tail won't average out in this case, because the variance of each of the cost inputs scales with volume instead of being diluted by it, and each of the inputs are unbounded.
Margins collapse at hyperscale
Margin collapse is the first and most obvious symptom of the problem. Cursor's repricing exposed poor margins, and we also learned that Replit's margins are volatile. And there is ample evidence that Anthropic is losing money on its subscriptions.
Each layer of the aggregate cost curve is highly variable, and the more you scale, the higher the probability that these tail risks can compound.
Think of every task as a coin-flip whose "size" is how many tokens it costs (X). Most tasks are small (X is a few hundred tokens), but a rare few are huge (tens of thousands).
X is a random variable because it's impossible to know the number of output tokens a task will consume when it's submitted. It's bounded by the context window limit, but the shape of the distribution leading up to that bound is still fat-tailed.
Mathematically:
Let C be the context window limit, and X be the token count for a single task (so 0 ≤ X ≤ C).
P(X > x) ~ k / x^α, where 1 < α < 2.
Let m be the total number of users and n be the total number of tasks. The aggregate token count is
S(m,n) = ∑(i=1 to mn) Xi (independent draws of X).
Consider B as the "break-even token count" (i.e., Total Revenue ÷ Price Per Token). B is the budget — when S(m,n) > B, the token seller loses money. For large budgets B (but still « C), the one-big-jump principle for heavy-tailed sums gives:
P(S(m,n) > B) ~ (mn) ⋅ P(X > B).
Meaning the probability of users' token usage exceeding the budget scales linearly with the number of draws. Said simply: more users and more tasks → more risk of financial loss.
Formally, applying scaling by a factor λ:
P(S(λm, λn) > B) ~ λmλn ⋅ P(S(m,n) > B).
Risk grows linearly with total tasks, whether those tasks come from new users or from existing users adding one more task: exactly the opposite of the law of large numbers safety net you'd expect at hyperscale.
Plugging in Plausible Numbers
α = 1.5
Context cap C = 200,000 tokens
Mean μ = 2,000 tokens (choose k ≈ 63 to match)
Daily budget B = 60,000 tokens per user-day
Single-Task Exceedance
P(a task costs more than 60,000 tokens) = P(X > 60,000) ≈ 63 / 60,000^1.5 ≈ 4.3 × 10^−7
Aggregate Exceedance at m Users, n Tasks Each
1,000 users × 30 tasks → 30,000 draws
P("loss") ≈ 30,000 × 4.3 × 10^−7 ≈ 1.3%
10,000 users × 300 tasks → 3,000,000 draws
P("loss") ≈ 3,000,000 × 4.3 × 10^−7 ≈ 100% (near-certain loss)
As Soren Larson put it:
There is a reason Cursor and Anthropic are the first to run into these issues publicly: code is instantly verifiable, and its feedback loop is addictive. There are engineers setting alarms for when their limits reset. Some have built dashboards to optimize their burn rate. Codegen is the first domain in AI-native software to reach hyperscale and outrun the underlying GPU supply.
Demand elasticity for code generation follows Jevons' paradox (i.e. for each efficiency gain, overall token consumption rises). We can see this clearly, as Cursor and Github comprise 45% of Anthropic's inference business.
There is a structural problem here: with elastic and nearly infinite demand, risk compounds. Product-Market Fit becomes a liability.
High variance forces startups to constrain demand
Many have written about the squeeze effect, but now we see it as a natural consequence of the variance issue. And the effect isn't limited to the application layer like Cursor and Replit: both model providers and integrators tie revenue to average tokens, but their costs are driven by highly variable usage.
The narrative that "Cursor raised prices because Anthropic raised theirs" gets the causality backwards. Cursor's users generated the extreme cost tail, because they had no usage limits in place; Anthropic's response was a downstream response, and Cursor's price hikes were forced re-pricings of the tail risk. Anthropic enforced new weekly limits after Cursor's re-pricings, indicating they still could not keep up with the demand.
Each movement is a pressurizing force. The model providers can either absorb the cost shock, or pass it downstream to integrators. The integrators have the same choice (albeit with less freedom).
Both get squeezed:
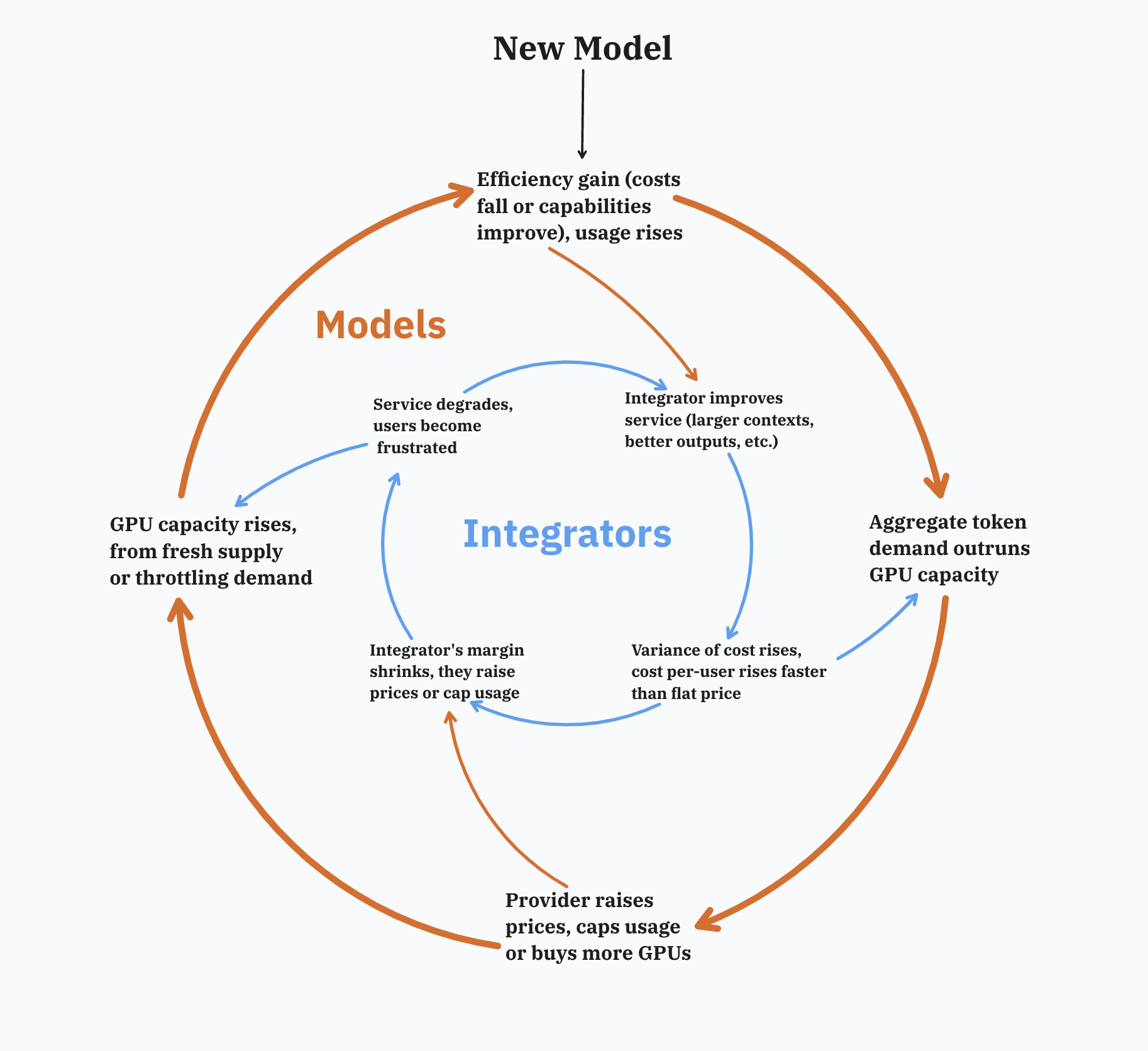
The dynamic is especially concerning for startups who face fat tail risk, and have no margin buffer to absorb it.
SF Compute's pricing section is the first vendor statement I've seen that acknowledges the token is not a fixed unit of cost. Their market-based prices expose the real cost drivers of inference (GPU supply, hardware efficiency etc.), in order to offer cheaper prices to developers.
As usage grows, though, the narrative flips from "cheaper on average" to "probable insolvency." Hand-wavey explanations like “power users” or “GPU scarcity” for driving the cost tail misses the point: varying costs across different requests is the true issue, and necessarily constrains demand.
Said another way: under finite, static pricing models, no one can raise prices nor throttle usage fast enough to keep up with the dynamic, growing cost curves.
Unpredictable costs kill traditional SaaS unit economics
Subscriptions misprice intelligence, and much of the industry recognizes this, but now we can rigorously explain why.
Traditional SaaS pricing mirrors the physics of stable software, but AI introduces high variance that breaks each of these laws.
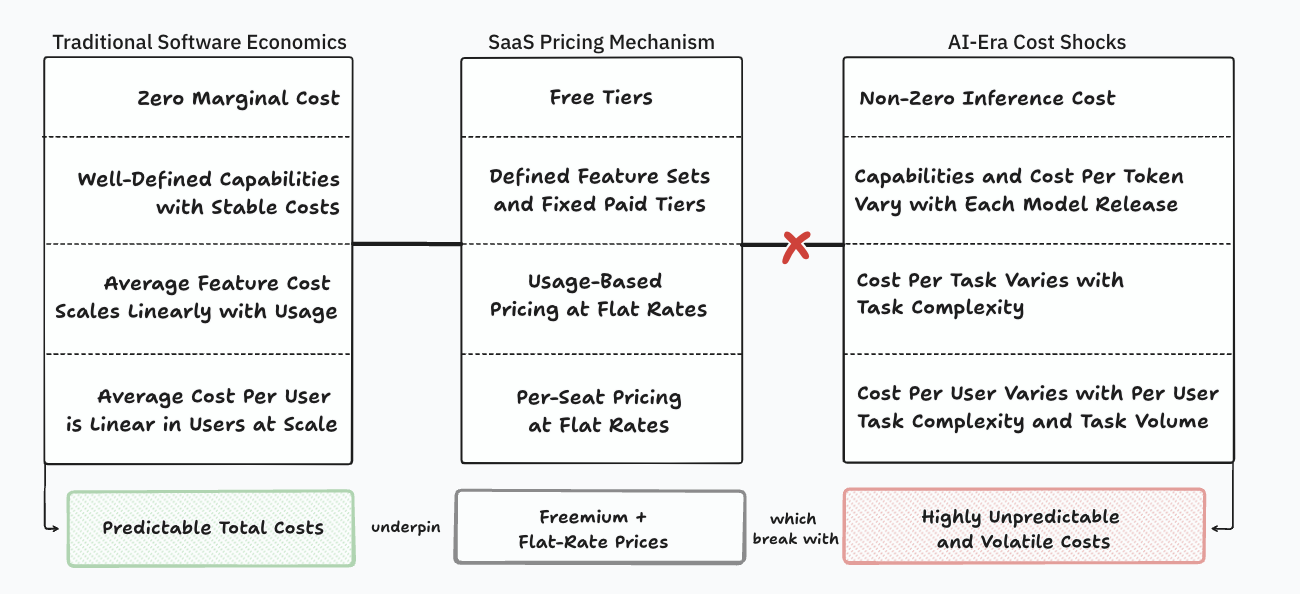
(this can be its own article. If someone else writes it, I’ll link it here).
It's a resource allocation problem
Anthropic endured constant outages and service interruptions, even after enforcing rate limits. This is inextricable from the fact that a token is not an atomic unit of cost.
Because a token is also not an atomic unit of compute.
Similar to how pricing structures treat a token as a fixed unit of cost, product interfaces treat the prompt and context as a static artifact whose size we can measure. But the inputs are more algorithmic than declarative; they dictate how much compute should be allocated to a given task.
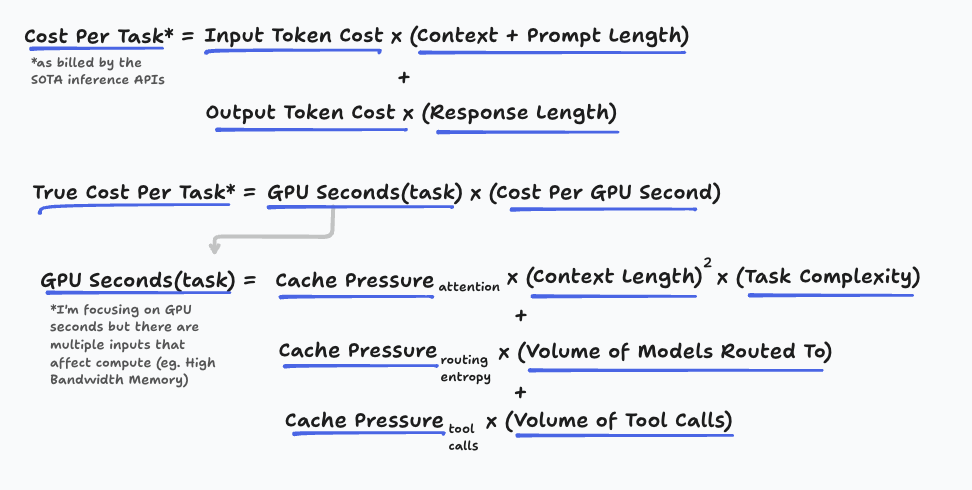
Soren likened applications like Cursor to affiliate marketing and used that metaphor to demonstrate the inevitable margin squeeze.
But the affiliate metaphor holds all the way down the stack. Each layer is just a pass-through to the scarce resource below it, and the scarcest resource under the current paradigm is GPU capacity and power.
The most straightforward way to lift margin and/or prevent outages is to silently dial down "intelligence": shorter chains, lower-quality responses, cheaper sampling. In late August, many users accused Anthropic of doing exactly that after they saw malformed answers, broken tool calls, and rising latency. Anthropic published an incident report, but complaints about degraded quality and service continued.
Soren explained "everyone is executing a brute-force/blunt 'hidden work' optimization: what's the least amount of compute I can get away with using such that my user doesn't churn?"
This is starting to sound like a market for lemons, where quality is unobservable, and price competition drives average quality to the floor.
The problem is that this degradation of service is hidden from users, so they have no incentive to optimize their requests to minimize compute. And users repeatedly ask for visibility: "Just show a dashboard with remaining weekly & Opus—stop making us guess."
But providers can't offer this, because costs are unpredictable for them too. It's invisible to everyone until the moment the system crashes without warning, leaving users frustrated and providers blindsided by the bill.
Usage caps are the resource allocator of last resort, but they're blunt. Unless the provider can reject or throttle requests before it starts executing, the cost from the exploding compute still materializes. The choice is who should shoulder it.
Towards a new pricing paradigm
High variance in costs necessarily constrains demand; today, the constraints are reactive.
To safely cushion from unbounded costs, a business model must price in the variance or be well above the true cost on average. Ideally by anchoring price to value delivered instead of token cost; but value delivered also happens to be highly variable and subjective. At the same time, there's structure to value: reliability, relevance, actionability.
The key insight is that margin squeeze and resource misallocation are two sides of the same problem. Solving one side of the equation should solve the other. If you can measure the value delivered, you can price that instead of raw compute. And if you can price outcomes in terms of value delivered, you can budget the exact amount of compute and data that maximizes profit on each task.
So the layer that owns the meter also decides how much compute and data to deploy and keeps the spread between cost and price. Today that meter sits inside the model; tomorrow it could sit inside an orchestrator that plans the whole workflow.
The implication is technologic, not economic: the scaling prize may go to whoever defines and measures “intelligence value,” not necessarily whoever trains the biggest, most capable model.
Soren Larson, @trickylabyrinth and Judah contributed significantly to this piece.
Thank you to @hypersoren, @trickylabyrinth and Judah for their work, and to Jason Harrison, Anthony Crognale, Suraj Srivats, Ade Oshineye and Alex Komoroske for offering feedback on early versions of this. And to Analogue Group, for the push to set out on this expedition.
View original draft with community comments and research notes.